
“Una mujer feliz y un hombre serio abrazados en un parque”. Que su ordenador ya sea capaz de describir de esta forma las fotos de sus viajes es genial. Y para muchas personas que navegan por internet usando lectores de pantalla es, además, una tecnología casi imprescindible. Todo esto gracias a la inteligencia artificial.
DUPAO EN WHATSAPP

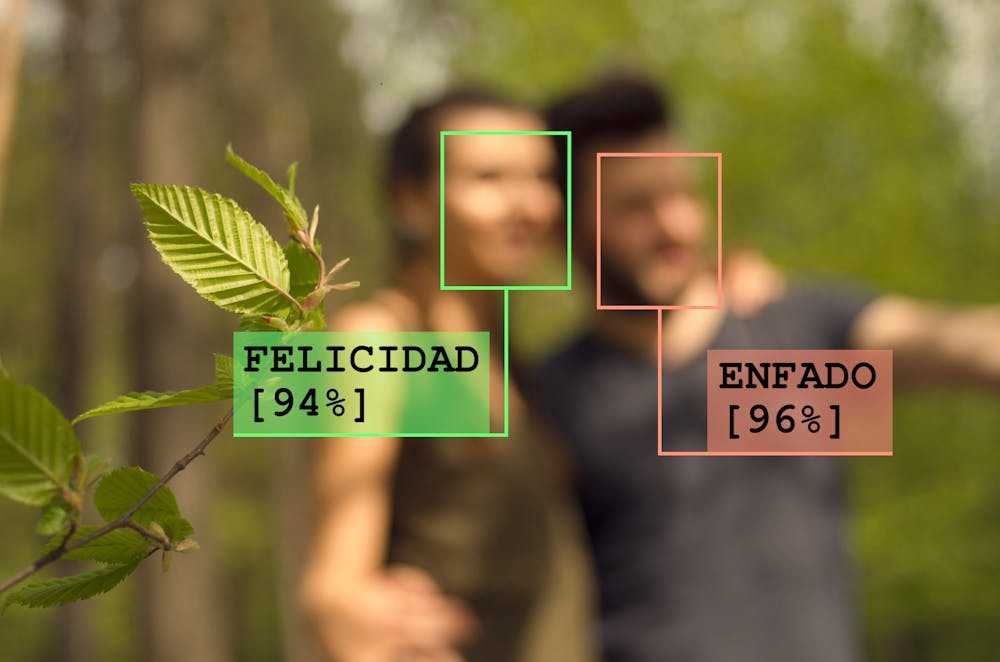
Por supuesto, las máquinas no son perfectas, a veces fallan. Pero últimamente estamos descubriendo algo preocupante: a veces los ordenadores fallan como falla un humano. Para una mujer y un hombre con la misma expresión, los sistemas de inteligencia artificial pueden tender a creer que ella está feliz y él de mal humor. A este tipo de errores les llamamos sesgos, e incluyen tendencias racistas, sexistas, capacitistas… que pueden acabar haciendo daño real a las personas.
La cara como espejo del alma
Para estudiar estos sesgos vamos a centrarnos en una aplicación concreta, el reconocimiento automático de emociones en fotografías.
Primero, necesitamos aclararle al ordenador a qué nos referimos con “emoción”. La clasificación más utilizada se basa en 6 emociones básicas: miedo, tristeza, alegría, enfado, asco y sorpresa. Esta clasificación fue propuesta por el psicólogo Paul Ekman en los 70.
Se ha demostrado que estas emociones son más o menos universales y todo el mundo las reconoce. Sin embargo, también se ha demostrado que se reconocen algo mejor entre personas del mismo grupo social, género, edad… No todos nos expresamos exactamente igual, ni leemos igual las expresiones del resto. Incluso sin darnos cuenta, estamos sesgados.
Estas diferencias se ven en muchos contextos, y en ocasiones se convierten en estereotipos y prejuicios. Por ejemplo, esperamos que las mujeres estén más felices que enfadadas, y lo contrario ocurre con los hombres. Y esto se refleja en internet, donde las fotos tienden a recoger, sobre todo, a mujeres sonrientes.
Por otro lado, para que un sistema de inteligencia artificial aprenda a distinguir estas emociones también necesitamos pensar en cómo las entendemos las personas. En realidad, la cara es solo una parte de un puzle muy complejo. También contribuyen los gestos, la postura, nuestras palabras… Aunque se trabaja en resolver todas estas modalidades con inteligencia artificial, la forma más popular y versátil es el reconocimiento basado en fotos de rostros.
Cómo aprende una inteligencia artificial
Crear una inteligencia artificial libre de sesgos es todo un reto. Y todo empieza con cómo hacemos para que esta tecnología “aprenda”. Al campo de la inteligencia artificial dedicado a este aprendizaje le llamamos machine learning. Aunque hay muchas formas distintas de aprendizaje, la más habitual es el aprendizaje supervisado.
La idea es simple: aprendemos a partir de ejemplos. Y la inteligencia artificial necesita saber para cada ejemplo, qué deseamos obtener. Para aprender a reconocer emociones, necesitamos un montón de fotos de caras con diferentes emociones: felicidad, tristeza, etc. La clave está en que para cada foto, debemos saber qué emoción aparece.
Después, le pasamos las fotos y sus emociones asociadas a la inteligencia artificial. Mediante un algoritmo de aprendizaje, el sistema irá aprendiendo “solo” a relacionar las fotos con las emociones que aparecen. Foto a foto, le pedimos que prediga una emoción: si acierta, seguimos adelante, y si falla, ajustamos el modelo para corregir este caso. Poco a poco, irá aprendiendo y fallará cada vez menos ejemplos. Si lo pensamos bien, no es tan diferente a cómo aprendemos los humanos.
Como se puede ver, en este proceso los ejemplos son fundamentales. Aunque existen avances que nos permiten aprender con pocos ejemplos, o ejemplos con errores, un conjunto de ejemplos grande y bien etiquetado es vital para conseguir una buena inteligencia artificial.
Por desgracia, en la práctica es habitual tener ejemplos con errores. En nuestro caso serían desde caras etiquetadas con la emoción equivocada hasta fotos sin caras o con caras de animales. Pero hay otros problemas, a veces más sutiles y preocupantes: racismo, sexismo, capacitismo…
Cuando los algoritmos se equivocan
Como se puede imaginar, si nuestros ejemplos están sesgados, la máquina aprenderá y reproducirá estos sesgos. En ocasiones, incluso multiplicará el efecto de los sesgos. Por ejemplo, si en nuestras fotos solo tenemos gente de piel oscura enfadada y gente de piel clara feliz, es muy probable que la inteligencia artificial acabe confundiendo el color de piel con el estado de ánimo. Tenderá a predecir enfado siempre que vea gente de piel oscura.
Desafortunadamente, esto no es solo una teoría. Ya se ha demostrado, por ejemplo, que los sistemas de análisis facial para reconocer el género fallan más para mujeres negras que para hombres blancos y que cometen errores regularmente con gente trans o de apariencia no normativa.
Uno de los ejemplos más sonados fue cuando en 2018 un sistema de inteligencia artificial identificó erróneamente a 28 congresistas estadounidenses como criminales. De los políticos identificados, el 40 % eran personas de color, aunque estos solo representaban el 20 % del Congreso. Todo esto porque el sistema se había entrenado sobre todo con personas blancas, y confundía entre sí a la gente de color.
Detectar y reducir estos sesgos es un campo de investigación muy activo y con gran impacto social. Muchos de ellos son sutiles y se relacionan con varios factores demográficos al mismo tiempo, por lo que es un análisis difícil. Además, hay que revisar todas las fases del aprendizaje, desde la recogida de datos y sus medidas hasta la aplicación final. Y normalmente no son las mismas personas las que trabajan en cada fase.
Una base de datos para incluirlos a todos
Volvamos al reconocimiento de emociones. En internet existen muchas bases de datos de emociones ya etiquetadas. Desgraciadamente, las bases de datos más grandes suelen tener también fuertes sesgos de sexo/género, raza y edad.
Es necesario que poco a poco desarrollemos bases de datos diversas y equilibradas sobre las que trabajar. Es decir, necesitamos incluir a todo tipo de personas en nuestras bases de datos. Además, todas ellas deben estar bien representadas en cada emoción.
Por último, si queremos recoger datos sin sesgos, hay que pensar en todo el proceso. Todas las fases, desde la toma de datos hasta las pruebas finales de una inteligencia artificial, deben realizarse de manera cuidadosa y accesible. Y es necesario involucrar a personas que puedan reconocer y señalar posibles sesgos en todas ellas.

Y todo esto ¿para qué?
Todo este asunto de reconocer emociones quizás suene abstracto, pero ya tiene aplicaciones importantes. La más habitual es la tecnología asistiva, como la descripción automática de fotos para personas con problemas de visión. También se usa ya en robots domésticos. Puede aplicarse incluso en medicina, donde se ha logrado reconocer automáticamente el dolor en recién nacidos que a veces no lo expresan a través del llanto.
De todas formas, el estudio de los sesgos en inteligencia artificial va más allá de las emociones. Las tecnologías que desarrollamos tienen un impacto enorme en la vida de las personas. Tenemos un deber moral de asegurarnos de que sean justas, de que su impacto en el mundo sea positivo.
Queremos construir una inteligencia artificial en la que podamos confiar, que nos haga sonreír.
Si quiere participar en la creación de una base de datos de emociones más justa y diversa, puede colaborar con el proyecto Emotional Films.
Mikel Galar Idoate, Profesor del Área de Ciencias de la Computación e Inteligencia Artificial, Universidad Pública de Navarra; Daniel Paternain, Associate professor, Universidad Pública de Navarra y Iris Dominguez Catena, Estudiante de Doctorado en Ciencias y Tecnologías Industriales, Universidad Pública de Navarra
Este artículo fue publicado originalmente en The Conversation. Lea el original.
¿Qué es DUPAO magazine? Somos la revista de Culturizando sobre Series y Películas, Ciencia y Tecnología, Marketing y Negocios, Productividad, Estilo de Vida y Tendencias.

Autor:
The Conversation


{kind=link}